Sunday, September 11, 2016
DBMS 1st annual 2015 paper solution

|
Q.No.1: Explain the following terms with examples |
Ans: Weak Entity:
An entity type whose instances cannot exist
without being linked with instances of some
other entity type, i.e., they cannot exist
independently. For example, in an organization
we want to maintain data about the vehicles
owned by the employees. Now a particular
vehicle can exist in this organization only if
the owner already exists there as employee.
Similarly, if employee leaves the job and the
organization decides to delete the record of
the employee then the record of the vehicle
will also be deleted since it cannot exist
without being linked to an instance of
employee.
Strong Entity Type:
An entity type whose instances can exist
independently, that is, without being linked to the instances of any other
entity type is called strong entity type. A major property of the strong entity
types is that they have their own identification, which is not always the case with
weak entity types. For example, employee in the previous example is an independent
or strong entity type, since its instances can exist independently.
Associative entity:
An entity type that associates the instances of
one or more entity types and contains attributes that are peculiar to the
relationship between those entity instances.
Locking:
A process in which any data that are retrieved
by a user for updating must be locked, or denied to other users, until the
update is completed or aborted. Locking data is much like checking a book out
of the library; it is unavailable to others until the borrower returns it.
Concurrency:
Concurrency in terms of databases means
allowing multiple users to access the data contained within a database at the
same time. If concurrent access is not managed by the Database Management
System (DBMS) so that simultaneous operations don't interfere with one another
problems can occur when various transactions interleave, resulting in an
inconsistent database.
Logical schema:
The representation of a database for a particular data management technology is called logical schema.
Conceptual schema:
A detailed, technology independent
specification of the overall structure of organizational
data.
Data definition language (DDL):
Commands used to define a database, including those for creating, altering, and dropping tables and establishing constraints.
Data manipulation language (DML):
Commands used to maintain and query a database, including those for updating, inserting, modifying, and querying data.
Q.No.2: What is
normalization? With the help of any example normalize data up to 3NF.
Normalization:
The process of decomposing relations with anomalies to produce smaller, well- structured relations.
Un-Normalized Form (UNF):
If a table contains non-atomic values at each
row, it is said to be in UNF. An atomic
value is
Something that cannot be further decomposed. A non-atomic value, as the name
suggests, can be further decomposed and simplified. Consider the following
table:
Emp-Id
|
Emp-Name
|
Month
|
Sales
|
Bank-Id
|
Bank-Name
|
E01
|
AA
|
Jan
|
1000
|
B01
|
SBI
|
Feb
|
1200
|
||||
Mar
|
850
|
||||
E02
|
BB
|
Jan
|
2200
|
B02
|
UTI
|
Feb
|
2500
|
||||
E03
|
CC
|
Jan
|
1700
|
B01
|
SBI
|
Feb
|
1800
|
||||
Mar
|
1850
|
||||
Apr
|
1725
|
In the sample table above, there are multiple
occurrences of rows under each key Emp-Id. Although considered to be the
primary key, Emp-Id cannot give us the unique identification facility for any
single row. Further, each primary key points to a variable length record (3 for
E01, 2 for E02 and 4 for E03).
First Normal Form (1NF)
A relation is said to be in 1NF if it contains no non-atomic values and each row can provide a unique combination of values. The above table in UNF can be processed to create the following table in 1NF.
Emp-Id
|
Emp-Name
|
Month
|
Sales
|
Bank-Id
|
Bank-Name
|
E01
|
AA
|
Jan
|
1000
|
B01
|
SBI
|
E01
|
AA
|
Feb
|
1200
|
B01
|
SBI
|
E01
|
AA
|
Mar
|
850
|
B01
|
SBI
|
E02
|
BB
|
Jan
|
2200
|
B02
|
UTI
|
E02
|
BB
|
Feb
|
2500
|
B02
|
UTI
|
E03
|
CC
|
Jan
|
1700
|
B01
|
SBI
|
E03
|
CC
|
Feb
|
1800
|
B01
|
SBI
|
E03
|
CC
|
Mar
|
1850
|
B01
|
SBI
|
E03
|
CC
|
Apr
|
1725
|
B01
|
SBI
|
As you can see now, each row contains unique
combination of values. Unlike in UNF, this relation contains only atomic values,
i.e. the rows cannot be further decomposed, so the relation is now in 1NF.
Second Normal Form (2NF):
A relation is said to be in 2NF f if it is already in 1NF and each and every attribute fully depends on the primary key of the relation. Speaking inversely, if a table has some attributes which is not dependent on the primary key of that table, then it is not in 2NF. Let us explain. Emp-Id is the primary key of the above relation. Emp-Name, Month, Sales and Bank-Name all depend upon Emp-Id. But the attribute Bank-Name depends on Bank-Id, which is not the primary key of the table. So the table is in 1NF, but not in 2NF. If this position can be removed into another related relation, it would come to 2NF.
Emp-Id
|
Emp-Name
|
Month
|
Sales
|
Bank-Id
|
E01
|
AA
|
Jan
|
1000
|
B01
|
E01
|
AA
|
Feb
|
1200
|
B01
|
E01
|
AA
|
Mar
|
850
|
B01
|
E02
|
BB
|
Jan
|
2200
|
B02
|
E02
|
BB
|
Feb
|
2500
|
B02
|
E03
|
CC
|
Jan
|
1700
|
B01
|
E03
|
CC
|
Feb
|
1800
|
B01
|
E03
|
CC
|
Mar
|
1850
|
B01
|
E03
|
CC
|
Apr
|
1725
|
B01
|
Bank-Id
|
Bank-Name
|
B01
|
SBI
|
B02
|
UTI
|
After removing the portion into another
relation we store lesser amount of data in two relations without any loss
information. There is also a significant reduction in redundancy.
Third Normal Form (3NF)
A relation is said to be in 3NF, if it is already in 2NF and there exists no transitive dependency in that relation. Speaking inversely, if a table contains transitive dependency, then it is not in 3NF, and the table must be split to bring it into 3NF.
What is a transitive dependency? Within a
relation if we see
A => B [B depends on A]
And
B => C [C depends on B]
Then we may derive
A => C[C depends on A]
Such derived dependencies hold well in most of
the situations. For example if we have
Roll => Marks
And
Marks => Grade
Then we may safely derive
Roll => Grade.
This
third dependency was not originally specified but we have derived it.
The derived dependency is called a transitive
dependency when such dependency becomes
improbable. For example we have been given
Roll => City
And
City => STDCode
If we try to derive Roll => STDCode it becomes a transitive dependency,
because obviously the
STDCode of a city cannot depend on the roll
number issued by a school or college. In such a case the relation should be
broken into two, each containing one of these two dependencies:
Roll =>City
And
City => TD code
Q.No.3 Explain ER model and its element. Also give
examples.
Entity Relationship Model:
An entity relationship Model is a logical
representation of data in an organization. It views the entire system as a
collection of entities related to one another. It is used to describe elements
of a system and their relationships. An entity in this context is a component
of data. In other words, ER Model illustrate the logical structure of
databases.
At first glance an entity relationship diagram
looks very much like a flowchart. It is the specialized symbols, and the
meanings of those symbols, that make it unique. An entity relationship diagram is a means of
visualizing how the information a system produces is related.
The History of Entity
Relationship Model
Peter Chen developed ERDs in 1976. Since then
Charles Bachman and James Martin have added some slight refinements to the
basic ERD principles.

|
Entity
|
Some examples of each of these kinds of
entities follow:
Person: EMPLOYEE, STUDENT, PATIENT
Place: STORE, WAREHOUSE, STATE
Object: MACHINE, BUILDING, AUTOMOBILE
Event: SALE, REGISTRATION, RENEWAL
Concept: ACCOUNT, COURSE, WORK CENTER
Entity is basic building block of the E-R data
model. The term entity is used in three different meanings or for three
different terms and that are:
·
Entity type
·
Entity instance
·
Entity set
Entity type:
A collection of entities that share common
properties or characteristics. Each entity type in an E-R model is given a
name. Because the name represents a collection (or
set) of items, it is always singular. We use capital letters for names of
entity type(s).
Example: All students in the same class share common
characteristics so class is consider as entity type.
Entity Types
|
Properties
|
Instances
|
EMPLOYEE
|
Human being, has
name, has father name, has are registration number, has qualification,
designation
|
Mr. Burhan , Mr.
Kashif and many others
|
FURNITURE
|
Used to sit or
work on, different material, having legs, cost, purchased
|
Chair, table etc.
|
ELECTRIC
APPLIANCES
|
Used for office
work, consumable or non-consumable,
|
Papers, pencil,
paper
weight etc.
|
Entity instance: An entity instance is a single occurrence of an entity type. Following table lists the entity types and their defining properties:
Entity Set: A group of entity instances of a particular
entity type is called an entity set.
Example: All employees of an organization form an entity set. Like all students, all courses, all of them form entity set of different entity types
Attribute:
Attributes, which are represented by ovals. A property or characteristic of an entity or relationship type that is of interest to the organization. Thus, an attribute has a noun name. Following are some typical entity types and their associated attributes.
Example:
STUDENT Student ID, Student
Name, Home Address, Phone Number, Major
AUTOMOBILE Vehicle ID, Color, Weight,
Horsepower
EMPLOYEE Employee ID, Employee
Name, Payroll Address, Skill
|
Attribute domain:
An
attribute domain is a set of all possible values for an attribute. All
attribute have domain. The domain may consist of range of values or some
discrete values.
Example: Domain for Grade point average (GPA) can be
from 0 to 4, similarly, the domain for gender attribute can be either male or
female.
Relationships:
A relationship is a logical connection between
different entities. The entities that participate in relationship are called
participants. The relationship may be between different entities or between an
entity itself. A relationship is establish on the basis of interaction among
these entities.
Example: A relationship exists between a STUDENT and TEACHER because the teacher teaches the students.
A relationship is called total if all entities
of that entity set may be participant in the relationship. A relationship is
called partial if some the entities of that entity set may be participant in
the relationship. Suppose a relationship SUPP PART exists between Supplier
and Part. The relationship is total
if every part is supplied by a supplier. The relationship is partial if certain
parts are available without a supplier.
Q.No.4: What is join? Describe its types in detail
Ans: Join is a combination of a Cartesian product
followed by a selection process. A Join operation pairs two tuples from
different relations, if and only if a given join condition is satisfied.
Theta (θ) Join:
Theta join combines tuples from different
relations provided they satisfy the theta condition. The join condition is
denoted by the symbol θ. In theta join we apply the condition on second
relation(s) and then only those selected rows are used in the cross product to
be merged and included in the output. It means that in normal cross product all
the rows of one relation are mapped/merged with all the rows of second
relation, but here only selected rows of a relation are made cross product with
second relation. It is denoted as under
Notation:
R1 ⋈θ R2
|
R1 and R2 are relations having attributes (A1,
A2, .., An) and (B1, B2,.. ,Bn) such that the attributes don’t have anything in
common, that is, R1 ∩ R2 = Φ. Theta join
can use all kinds of comparison operators.



Equi join:
When Theta join uses only equality comparison operator, it is
said to be equijoin. The above example corresponds to equijoin.
Natural Join (⋈):
Natural join does not use any comparison
operator. It does not concatenate the way a Cartesian product does. This is the
most common and general form of join. If we simply say join, it means the natural
join. It is same as equi–join but the difference is that in natural join, the
common attribute appears only once. We can perform a Natural Join only if there
is at least one common attribute that exists between two relations. In
addition, the attributes must have the same name and domain. Natural join acts on those matching attributes
where the values of attributes in both the relations are same


Outer Joins
:
Theta Join, Equijoin, and Natural Join are
called inner joins. An inner join includes only those tuples with matching
attributes and the rest are discarded in the resulting relation. Therefore, we
need to use outer joins to include all the tuples from the participating relations
in the resulting relation. There are three kinds of outer joins: left outer
join, right outer join, and full outer join.
Left Outer Join ( R⋈S ):
All the tuples from the Left relation, R, are
included in the resulting relation. If there are tuples in R without any
matching tuple in the Right relation S, then the S-attributes of the resulting
relation are made NULL.



Right Outer Join: (R⋈S):
All the tuples from the Right relation, S, are
included in the resulting relation. If there are tuples in S without any matching
tuple in R, then the R-attributes of resulting relation are made NULL.

All the tuples from both participating
relations are included in the resulting relation. If there are no matching
tuples for both relations, their respective unmatched attributes are made NULL.
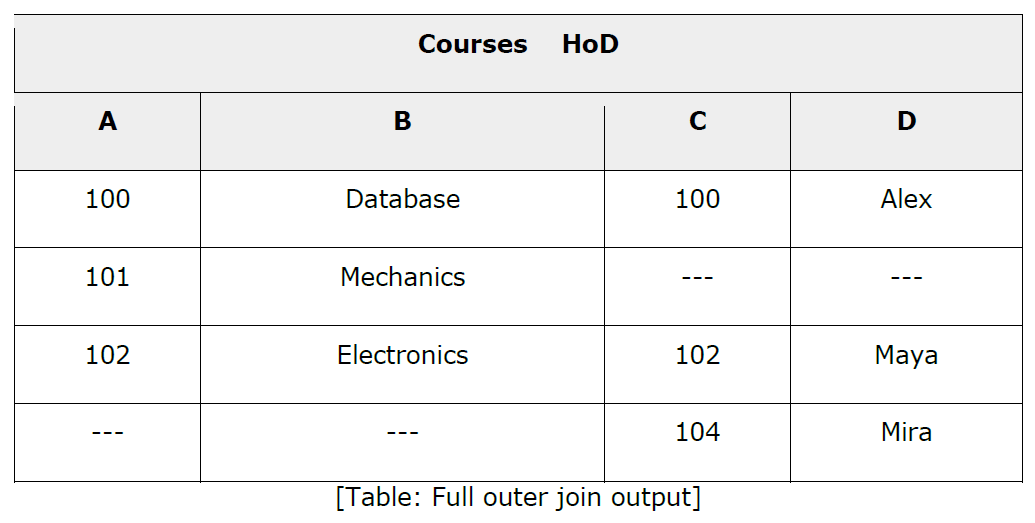
Q.No.5: Write down the difference between conventional
file processing system and DBMS.
Conventional file
processing system
|
Database
management system
|
1.
A computerized
record-keeping system
|
1.
Set of individual
programs and data handled by programmers.
|
2.
Data and Programs
were interconnected and interdependent, change in one often required change
in the other which obviously meant extra costs, time and resource wastage.
|
2.
Program and data
are independent of each other in
Database management system. So the change one not required to change in other
which meant no extra cost, time and resource wastage is required.
|
3.
As data about the
same entity could be stored in different files / locations, it caused
potential data inconsistency because often the data was not updated in all
the different locations it was stored.
|
3.
Data is stored at
one place so it does not
Caused data inconsistency.
|
4.
It does not
provide multiple user interfaces
|
4.
It provide
multiple user interfaces
|
5.
Data is not access
easily because special programs needed to access data
|
5.
Data is easily
accessed due to standard query procedures
|
6.
File system does
not provide high security
|
6.
DBMS provide high
security features
|
7.
It does not
provide concurrent access of data to multiple users
|
7.
It provide
concurrent access of data to multiple users
|
8.
It does not
provide the ability to apply integrity constrains on data.
|
8.
It provide the
ability to apply integrity constrains on data from field level to table
|
9.
It does not
provide the facility to share data.
|
9.
It provide the
facility to share data.
|
Q.No.6: What are the properties of relation? Discuss
it.
1. Unique name of relation:
Each relation (or table) in a database has a
unique name to uniquely access the required data when needed. This property
simplifies data access so developers and users can easily access data uniquely.
2. Values Are Atomic:
An entry at the intersection of each row and
column is atomic (or single valued).
There can be only one value associated with
each attribute on a specific row of a Table; no multivalued attributes are
allowed in a relation. The key benefit of the one value property is that it
simplifies data manipulation logic. Such tables are referred to as being in the
“first normal form” (1NF).
3. Column Values Are of the Same Kind:
In relational terms this means that all values
in a column come from the same domain. A domain is a set of values which a
column may have. This property simplifies data access because developers and
users can be certain of the type of data contained in a given column. It also
simplifies data validation. Because all values are from the same domain, the
domain can be defined and enforced with the Data Definition Language (DDL) of
the database software.
4. Each Row is Unique:
This property ensures that no two rows in a
relational table are identical; there is at least one column, or set of
columns, the values of which uniquely identify each row in the table. Such
columns are called primary keys. This property guarantees that every row in a
relational table is meaningful and that a specific row can be identified by
specifying the primary key value.
5. The Sequence of Columns is Insignificant:
This property states that the ordering of the
columns in the relational table has no meaning. Columns can be retrieved in any
order and in various sequences. The benefit of this property is that it enables
many users to share the same table without concern of how the table is
organized. It also permits the physical structure of the database to change
without affecting the relational tables.
6. The Sequence of Rows is Insignificant:
This property is
similar to the above one but applies to rows instead of columns. The main
benefit is that the rows of a relational table can be retrieved in different
order and sequences. Adding information to a relational table is simplified and
does not affect existing queries.
7. Each Column Has a Unique Name:
Because the sequence of columns is
insignificant, columns must be referenced by name and not by position. A column
name need not be unique within an entire database but only within the table to
which it belongs
Q.No.7: What is three level architecture? Discuss
Ans: An early proposal for
a standard terminology and general architecture database a system was produced
in 1971 by the DBTG (Data Base Task Group) appointed by the Conference on data
Systems and Languages. The DBTG recognized the need for a two level approach
with a system view called the schema and user view called subschema. The American
National Standard Institute recognized the need for a three level approach with
a system catalog. The standard Planning and Requirements Committee of American
National Standards Institute (ANSI) Committee on Computers and
Information Processing developed and published a similar vocabulary and
architecture in 1975.

The results of these
reports was the three-level architecture. Three-level Architecture is a basis
of modern database architectures. Database can be viewed at three levels. These
three levels are depicted by three models known as Three-level Schema. These
models can refer the structures of the database systems not the data stored in
it. The permanent structure of database is also known as Intension of Database
or Database Schema. The data can be stored at given time known as
Extension of Database or Database Instance. The intensions of database should
not be changed once it has been defined. This because a small change in the
intension of database may require many changes to the data stored in the
databases. The extension of database is performed after the intension of
database has been finished. It means that data is stored in database when the
database structure has been defined. The extension of database is performed
according to the rules defined in the intension of database. The schema's are
used to store definitions of the structures of databases. It can be anything a
like a single entity or the whole organization. Three level architecture
defines the many different schemas stored at different levels to isolate the
details of different levels from one another.
The External Level (User Representation of
Data):
It is the
highest level of abstraction that deals with the user’s view of the database
and thus, is also known as view level. One user may not be full aware of whole
system. Each user has its own view about system for example one user may thing
dates are stored in (Days/month/year) format and other user thing that dates
are stored in (Year/Month/Days)
Format. Some views
might include virtual data. Virtual data is the data which is not actually
stored in database but can be calculated from available data as and when required.
For
Example: Age of employee can
be calculated from date of birth when needed.
In general, most of
the users and application programs do not require the entire data stored
in the database. The external level describes a part of the database for a
particular group of users. Multiple users can work on a database on the same
time because of it. The external level also hides the working of the database
from your users. It maintains the security of the database by giving users
access only to the data which they need at a particular time. Any data that is
not needed will not be displayed.
Example:
·
Students should not
see faculty salaries.
·
Faculty should not
see billing or payment data
The Conceptual Level (Holistic Representation
of Data):
Conceptual level is
the complete description of data stored in database. It shows complete view of
database that is why it is also known as community view. This level of
abstraction deals with the logical structure of the entire database and thus,
is also known as logical level. It describes what data is stored in the database,
the relationships among the data and complete view of the user’s
requirements without any concern for the physical implementation. That is,
it hides the complexity of physical storage structures. The conceptual
view is the overall view of the database and it includes all the
information that is going to be represented in the database. The database administrator will have to be
conscious about this layer, because most of his operations are carried out on
it. Only a database administrator is allowed to modify or structure this level.
It provides a global view of the database, as well as the hardware and software
necessary for running it. The conceptual view shows all exiting entities in
organization, their attributes and their relationships.
Example: We can take example of a customer, now
conceptual schema will have all the detail of products present in the stock,
product which are ready to be delivered, salespersons of the company and
everything associated which is associated with the business of the company in
any way. Now we know that Customers buy product from outlet of the company,
thus in such a case a specific customer has a relationship with that specific
outlet of the company.
The conceptual schema manages all such
relationships and maps these relationships among member entities. The
conceptual schema as it describe intension of the database so it is not changed
often, because change in conceptual schema of the database required lots of
consideration and may involve changes to other views of the database. The
conceptual schema describe the following things
·
Entities and their relationships
·
Semantic data ( Meta data)
·
Access of different users
·
Integrity constrains on database
The Internal Level (Physical Representation of
Data):
It is the lowest level of data abstraction that
deals with the physical representation of the database on the computer and
thus, is also known as physical level. This level deals with how the
stored data on the database is represented to the user. This level shows
exactly how the data is stored and organized for access on your system. This is the most technical of the three levels.
Although the internal
and physical level are so close and generally referred to a single layer of
DBMS but there is slight a difference between them. As we know that data when
stored into magnetic media is stored in binary format, because this is the only
format which can be represented electronically. No matter what is the actual
format of data, either text, images, audio or video. This binary storage
mechanism is always implemented by the operating system of the computer. DBMS
to some extend decides the way data is to be stored on disk. This decision of
DBMS is based on requirements specified by DBA when implementing database.
Moreover the DBMS itself adds information to the data which is to be stored.
For example a DBMS has selected a specific file organization for storage of
data on disk. To implement specific file system DBMS needs to create specific
indexes. Now whenever DBMS want to retrieve information it will use same
specific indexes to retrieve information. This index information is an example of
additional information which DBMS place in the data when storing it on disk. At this level,
various aspects are considered to achieve optimal runtime performance and
storage space utilization. These aspects include storage space allocation
techniques for data and indexes, access paths such as indexes, data
compression and encryption techniques, and record placement. Most DBMS
software products make sure that data access is optimized and that data uses
minimum storage space. The OS you’re running is actually in charge of managing
the physical storage space.
Q.No.8: Define the following terms with examples.
Primary key:
An attribute or a combination of attributes
that uniquely identifies each row in a relation.
A primary key attributes are required NOT NULL
AND UNIQUE. That is primary key attribute cannot be left null and it cannot
contain duplicate values.
Example: The primary key for the relation EMPLOYEE1 is EmpID.
We express this relation as follows:
EMPLOYEE1 (EmpID, Name, DeptName, Salary).
Alternate key:
The key which can uniquely identify a tuple or
record in a relation and not selected as a primary key is called an alternate
key.
Example: Suppose a relation student has the following attribute Registration-No, roll no, name,
class etc. so if attribute registration-No may be selected as primary key then
Roll-no will be an alternative key because it
can also uniquely identify a tuple in a relation.
Data atomicity:
A transaction is a
set of steps to perform a specific operation on data. But sometimes due to
power failure all steps of transaction is not perform which causes data
inconsistency for example a transition of transferring money from A
account to account B it consist of two steps as follows
1.
Remove money from
account A
2.
Add money in account B
If one step is performed and system fail it
means data is inconsistent this power failure leads us to data atomicity.
Locking:
A process in which any data that are retrieved
by a user for updating must be locked, or denied to other users, until the
update is completed or aborted. Locking data is much like checking a book out
of the library; it is unavailable to others until the borrower returns it.
One to one relationship:
One to one relationship is defined as for one
instance of an entity A there will be only one instance of an
entity B and for one instance of an
entity B there is only one instance
of an entity A

One to many relationship:
One to many relationship is defined as for one
instance of an entity A there will be many instance of an entity B and for many instance of an entity B there is only one instance of an
entity A.

Active data dictionary:
An active data dictionary is managed automatically by the
database management software. Active systems are always consistent with the
current structure and definition of the database because they are maintained by
the system itself.
Passive data dictionary:
A passive data dictionary is managed by the user(s)
of the system and is modified whenever the structure
of the database is changed. Because this modification must be performed
manually by the user, it is possible that the data dictionary will not be
current with the current structure of the database. However, the passive data
dictionary may be maintained as a separate database. This may be desirable
during the design phase because it allows developers to remain independent from
using a particular RDBMS for as long as possible.
Subscribe to:
Post Comments
(
Atom
)








No comments :
Post a Comment